Documented results.
Structure did the work.
Three measurements from live deployments. No ad spend. No link building. Graph architecture alone.
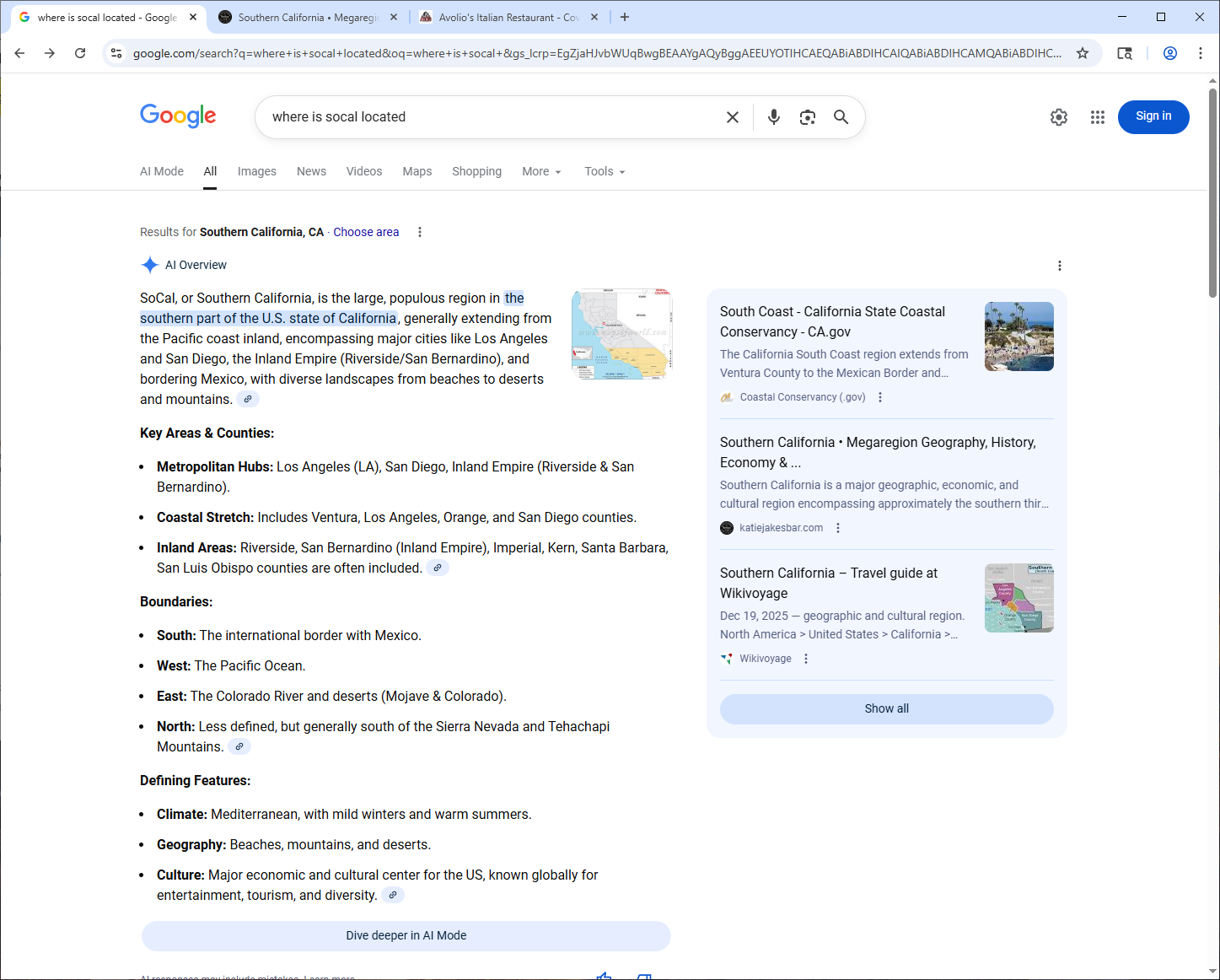
A local bar built with graph architecture appeared in Google AI summaries alongside WikiVoyage. Zero ad spend. Zero link building. The structure made it happen inside two months of launch.
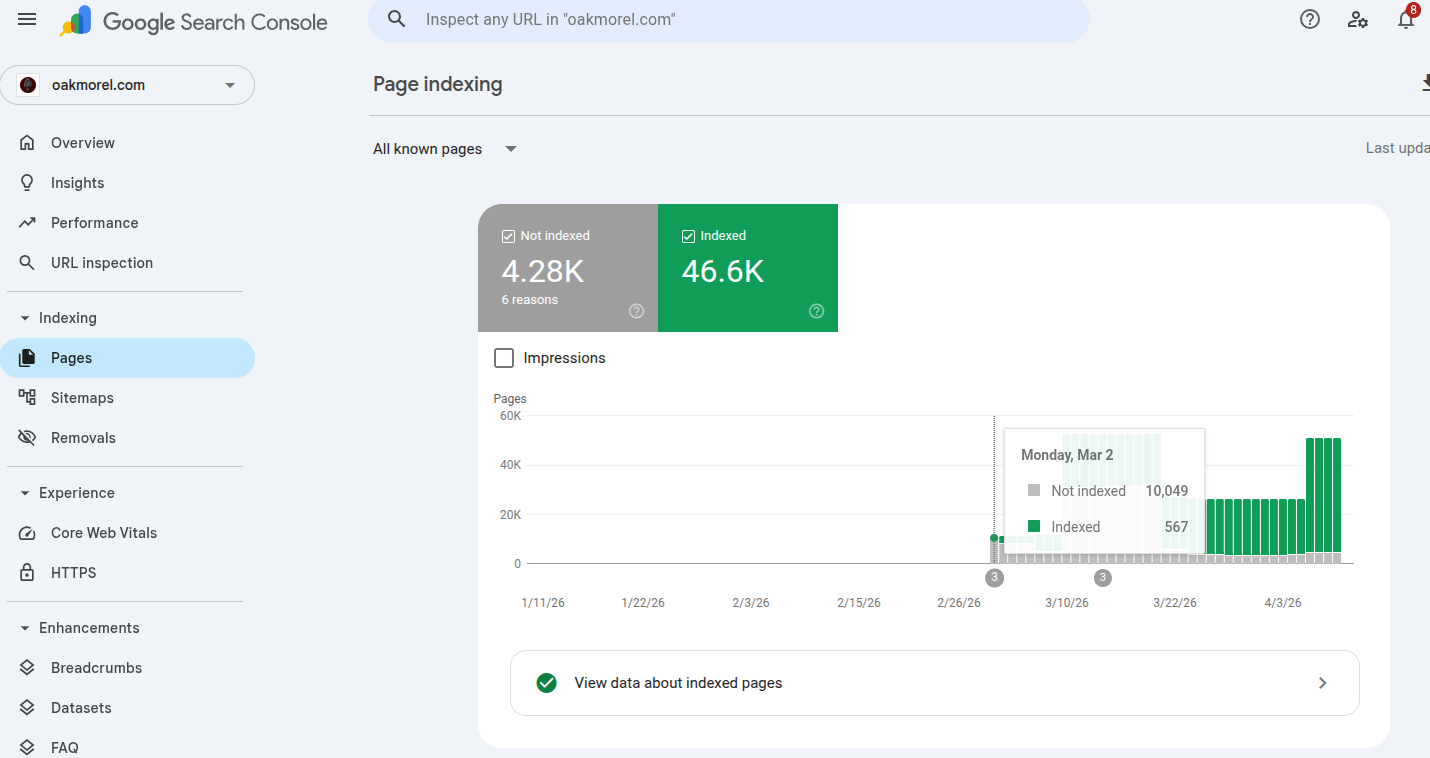
46,600 pages indexed by Google in under two months from a standing start. Declared relationships and full provenance — crawlers follow the edges at a speed that defies conventional expectation.
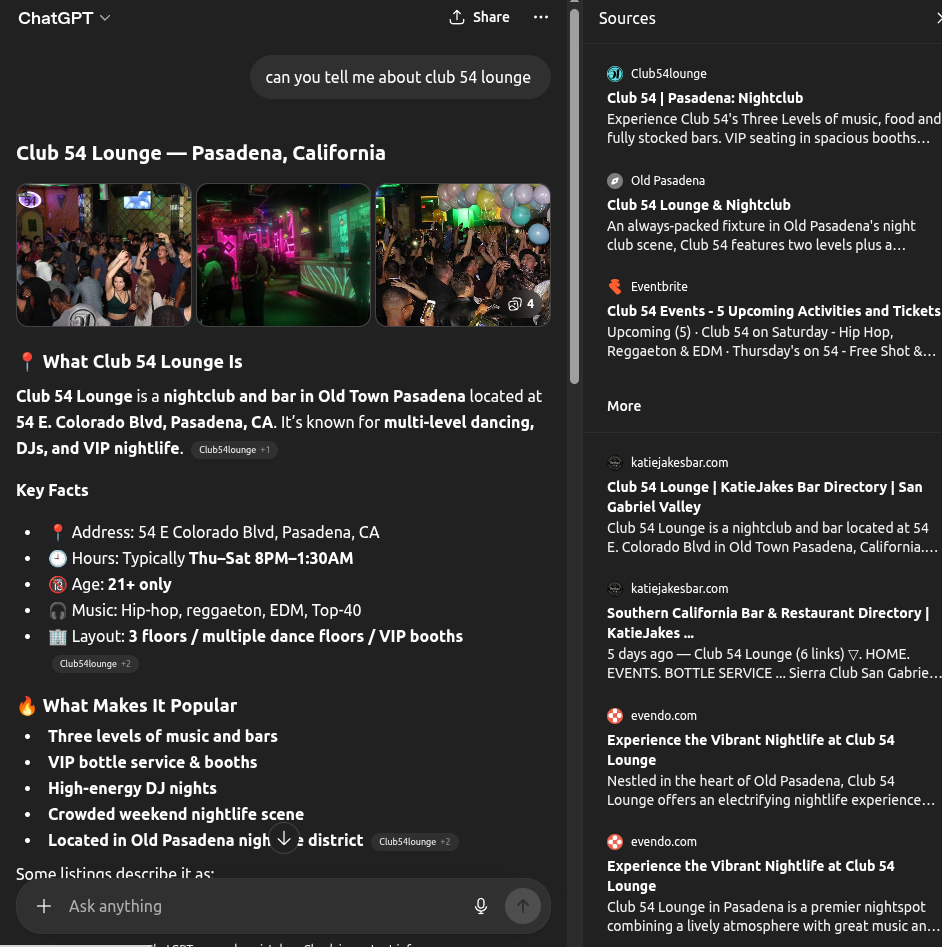
A user queried ChatGPT about a completely different bar. A graph-structured directory surfaced as a cited source. The graph made it the most authoritative structured source for that category. That is what being the substrate means.
Every business in every category is competing for one answer at a time. The graph architecture doesn't compete for answers. It becomes the substrate from which all answers in a category are generated — permanently, repeatedly, compounding. The difference between a result and a source is structure.